Use Cases
AICC Scenario
Call Center Data Analysis
Introduction
In today’s data-driven world, effective customer service is a critical component of any successful business. Call centers, which handle customer inquiries and issues, generate vast amounts of data. This use case will guide you through analyzing call center data using ThanoSQL, a powerful tool for managing and querying data. We will classify call transcripts into categories using various language models (LLMs), and derive key performance metrics such as average call time, satisfaction score, and resolution rate for each category. This analysis can provide valuable insights into customer interactions, helping to improve service quality and overall customer satisfaction.This tutorial can be executed both within ThanoSQL Lab and in a local Python/Jupyter environment. Whether you prefer to work directly within ThanoSQL Lab’s integrated environment or set up a local development environment on your machine, the instructions provided will guide you through the necessary steps.
If you want to try running the code from this use case, you can download the complete Jupyter notebook using this link: Download Jupyter Notebook. Alternatively, you can download it directly to your machine using the
wget command below:To run the models in this tutorial, you will need the following tokens:
- OpenAI Token: Required to access all the OpenAI-related tasks when using OpenAI as an engine. This token enables the use of OpenAI’s language models for various natural language processing tasks.
- Huggingface Token: Required only to access gated models such as Mistral on the Huggingface platform. Gated models are those that have restricted access due to licensing or usage policies, and a token is necessary to authenticate and use these models. For more information, check this Huggingface documentation. Make sure to have these tokens ready before proceeding with the tutorial to ensure a smooth and uninterrupted workflow.
Dataset
We will be working with the following datasets:- Counseling Staff Information Table (agents): Contains details about the call center agents.
agent_id: Unique identifier for each agent.agent_name: Name of the agent.
- Consultation Call Metadata Table (calls): Records metadata for each call.
call_id: Unique identifier for each call.agent_id: Identifier linking the call to the agent.satisfaction_score: Customer satisfaction score for the call.call_duration: Duration of the call.resolution_rate: Rate at which the call issue was resolved.
- Consultation Call Transcription Table (transcript): Contains the text of the conversations.
call_id: Identifier linking the call to the transcription.conversation: Text of the conversation during the call.
Goals
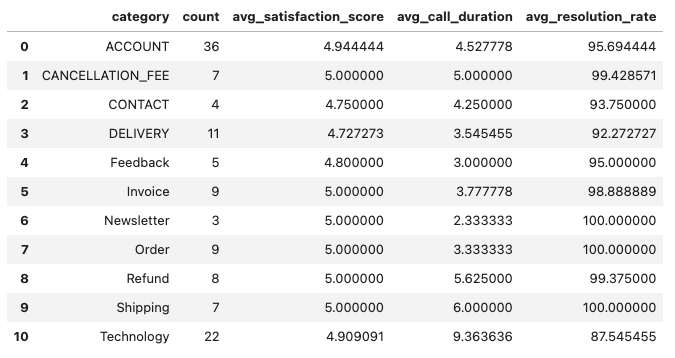
- Classify call transcripts into meaningful categories using LLMs.
- Calculate and analyze the average call time, satisfaction score, and resolution rate for each category.
Displaying ThanoSQL Query Results in Jupyter Notebooks
The check_result function is designed to handle and display the results of a database query executed via the ThanoSQL client. It ensures that any errors are reported, and successful query results are displayed in a user-friendly format. Note: This function is specifically designed to work in Jupyter notebook environments.Procedure
-
Import ThanoSQL Library:
- Import the ThanoSQL library and create a client instance. This client will be used to interact with the ThanoSQL engine.
-
Upload Data to Tables:
- Upload the
agentstable which contains details about the call center agents.
On execution, we get:
-
This step uploads the
agentsdata to ThanoSQL and retrieves the first 10 records to confirm the upload. -
Upload the
callstable which records metadata for each call.
On execution, we get:
-
This step uploads the
callsdata to ThanoSQL and retrieves the first 10 records to confirm the upload. -
Upload the
transcripttable which contains the text of the conversations.
On execution, we get:
- This step uploads the
transcriptdata to ThanoSQL and retrieves the first 10 records to confirm the upload.
- Upload the
-
Classify Conversations and Aggregate Metrics:
- Classify conversations using the Mistral LLM and calculate performance metrics.
-
Using Mistral LLM:
On execution, we get:
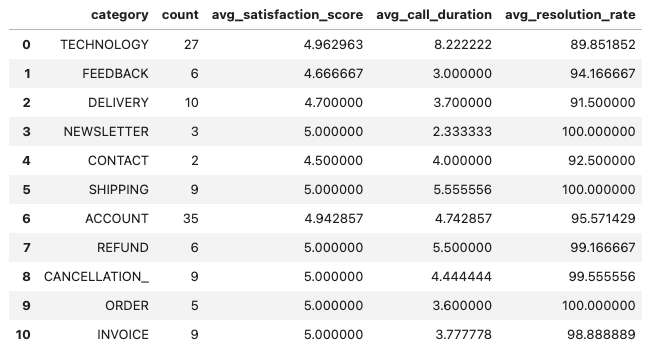
- Classify conversations using the OpenAI GPT-4o and calculate performance metrics.
-
Using OpenAI GPT-4o:
On execution, we get: